Apache Hadoop 2/ YARN/MR2 Installation for Beginners :
Background:
Big Data spans three dimensions: Volume, Velocity and Variety. (IBM defined 4th dimension or property of Big Data i.e Veracity). Apache™ Hadoop® is an open source software project that enables the distributed processing of large data sets (Big Data) across clusters of commodity Machines(Low-cost Servers). It is designed to scale up to thousands of machines, with a high degree of fault tolerance and software has the intelligence to detect & handle the failures at the application layer.
Big Data spans three dimensions: Volume, Velocity and Variety. (IBM defined 4th dimension or property of Big Data i.e Veracity). Apache™ Hadoop® is an open source software project that enables the distributed processing of large data sets (Big Data) across clusters of commodity Machines(Low-cost Servers). It is designed to scale up to thousands of machines, with a high degree of fault tolerance and software has the intelligence to detect & handle the failures at the application layer.
NOTE: More details are available@http://hadoop.apache.org/docs/stable/
- The Apache Hadoop component introduced two new terms for Hadoop 1.0 users - MapReduce2 (MR2) and YARN.
- Apache Hadoop YARN is the next-generation Hadoop framework designed to take Hadoop beyond MapReduce for data-processing- resulted in better cluster utilization that permit Hadoop to scale to accommodate more and larger jobs.
- This blog provides information for users to migrate their Apache Hadoop MapReduce applications from Apache Hadoop 1.x to Apache Hadoop 2.x


Steps to Install Hadoop2.0 on CentOS/RHEL6 on single node Cluster setup:
Set the environment variable $JAVA_HOME properly
NOTE: Java-1.6.0-openjdk OR other Hadoop Java Versions listed in a below link are more preferable.
http://wiki.apache.org/hadoop/HadoopJavaVersions
Step2: Download Apache Hadoop2.2 to folder $PACKAGE_HOME from link : http://hadoop.apache.org/releases.html#Download
Step 3: Add all hadoop and java environment path variables to .bashrc file.
Example :
Configure $HOME/.bashrc
- HODOOP_HOME
- JAVA_PATH
- PATH
- HADOOP_HDFS_HOME
- HADOOP_YARN_HOME
- HADOOP_MAPRED_HOME
- HADOOP_CONF_DIR
- YARN_CLASS_PATH
------------------------------------------------------------------------------------------
Step 4 : Create a separate Group for Hadoop setup
# groupadd hadoop
Step 5: Add 3 user-accounts in Group "hadoop"
# useradd -g hadoop yarn
# useradd -g hadoop hdfs
# useradd -g hadoop mapred
NOTE: Its good to run daemons with a related accounts
Step 6: Create Data Directories for namenode,datanode and secondary namenode
# mkdir -p $CONFIG/data/hadoop/hdfs/nn
# mkdir -p $CONFIG/data/hadoop/hdfs/dn
# mkdir -p $CONFIG/data/hadoop/hdfs/snn
Step 7: Set permission for "hdfs" account
# chown hdfs:hadoop $CONFIG/data/hadoop/hdfs -R
Step 8: Create Log Directories
# mkdir -p $CONFIG/log/hadoop/yarn
# mkdir logs (at installation directory Example $PACKAGE_HOME/hadoop2.2.0/logs)
Step 9: Set ownership to yarn
# chown yarn:hadoop $CONFIG/log/hadoop/yarn - R
Step 9: Set ownership to yarn
# chown yarn:hadoop $CONFIG/log/hadoop/yarn - R
Go to Hadoop directory "$PACKAGE_HOME/hadoop2.2.0/ "
# chmod g+w logs
# chown yarn:hadoop . -R
Step 10: Configure below listed XML files at $HADOOP_PREFIX/etc/hadoop

------------------------------------------------------------------------------------------------------------------
i) core-site.xml

ii) hadoop-env.sh
[root@spb-master hadoop]# cat hadoop-env.sh
# Copyright 2011 The Apache Software Foundation
export JAVA_HOME=$BIN/java/default
export HADOOP_PREFIX=$PACKAGE_HOME/hadoop-2.2.0
export HADOOP_HDFS_HOME=$PACKAGE_HOME/hadoop-2.2.0
export HADOOP_COMMON_HOME=$PACKAGE_HOME/hadoop-2.2.0
export HADOOP_MAPRED_HOME=$PACKAGE_HOME/hadoop-2.2.0
export HADOOP_YARN_HOME=$PACKAGE_HOME/hadoop-2.2.0
export HADOOP_CONF_DIR=$PACKAGE_HOME/hadoop-2.2.0/etc/hadoop/
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
export HADOOP_LOG_DIR=$PACKAGE_HOME/hadoop-2.2.0/logs
# The maximum amount of heap to use, in MB. Default is 1000.
export HADOOP_HEAPSIZE=500
export HADOOP_NAMENODE_INIT_HEAPSIZE="500"
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE="200"
------------------------------------------------------------------------------------------------------------------------ iii) hdfs-site.xml
[root@spb-master hadoop]# cat hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:$DATA_DIR/data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:$DATA_DIR/data/hadoop/hdfs/dn</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
[root@spb-master hadoop]#
iv) mapred-site.xml

v) yarn-env.sh
[root@spb-master hadoop]# cat yarn-env.sh
export JAVA_HOME=$BIN/java/default
export HADOOP_PREFIX=$PACKAGE_HOME/hadoop-2.2.0
export HADOOP_HDFS_HOME=$PACKAGE_HOME/hadoop-2.2.0
export HADOOP_COMMON_HOME=$PACKAGE_HOME/hadoop-2.2.0
export HADOOP_MAPRED_HOME=$PACKAGE_HOME/hadoop-2.2.0
export HADOOP_YARN_HOME=$PACKAGE_HOME/hadoop-2.2.0
export HADOOP_CONF_DIR=$PACKAGE_HOME/hadoop-2.2.0/etc/hadoop/
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
JAVA=$JAVA_HOME/bin/java
JAVA_HEAP_MAX=-Xmx500m
# For setting YARN specific HEAP sizes please use this
# Parameter and set appropriately
YARN_HEAPSIZE=500
vi) yarn-site.xml
---------------------------------------------------------------------------------------------------------------
Step 11: Create a passwordless ssh session for "hdfs" user account :
# su - hdfs
hdfs@localhost$ ssh-keygen -t rsa
hdfs@localhost$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
hdfs@localhost$ chmod 0600 ~/.ssh/authorized_keys
ssh-copy-id -i /home/user1/.ssh/id_rsa.pub hostname1
ssh-copy-id -i /home/user1/.ssh/id_rsa.pub hostname2
ssh-copy-id -i /home/user1/.ssh/id_rsa.pub hostname3
NOTE: It's important to remember that /home/USER must be 700 or 755 –
[root@ibmgpu01 ~]# chmod 755 /pmpi2/smpici
---------------------------------------------------------------------------------Step 12:
Now you are allowed to login without prompting for the password :
[hdfs@localhost]$ ssh localhost
Last login: Sun Dec 29 04:31:44 2013 from localhost
[hdfs@localhost ~]$
---------------------------------------------------------------------------------------------------------------
Step 13: Format Hadoop File system :
Format the NameNode directory as the HDFS superuser ( "hdfs" user account)
#su - hdfs
$ cd $PACKAGE_HOME/hadoop2.2/bin
$./hdfs namenode -format
It should show the message : $CONFIG/data/hadoop/hdfs/nn has been successfully formated as shown below:
[hdfs@localhost bin]$ ./hdfs namenode -format
13/12/29 02:36:52 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost.localdomain/127.0.0.x
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.2.0
STARTUP_MSG: classpath = $PACKAGE_HOME/hadoop-2.2.0/etc/hadoop/:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/common/lib/jetty-6.1.26.jar:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/common/lib/commons-el-1.0.jar:
STARTUP_MSG: java = 1.7.0_45
************************************************************/
13/12/29 02:36:52 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library //hadoop-2.2.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
13/12/29 02:36:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Formatting using clusterid: CID-d47a364a-edc6-455f-b3c8-4d2ba54458d5
13/12/29 02:36:54 INFO namenode.HostFileManager: read includes:
HostSet(
)
13/12/29 02:36:54 INFO namenode.HostFileManager: read excludes:
HostSet(
)
13/12/29 02:36:54 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
13/12/29 02:36:54 INFO util.GSet: Computing capacity for map BlocksMap
13/12/29 02:36:54 INFO util.GSet: VM type = 64-bit
13/12/29 02:36:54 INFO util.GSet: 2.0% max memory = 96.7 MB
13/12/29 02:36:54 INFO util.GSet: capacity = 2^18 = 262144 entries
13/12/29 02:36:54 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
13/12/29 02:36:54 INFO blockmanagement.BlockManager: defaultReplication = 1
13/12/29 02:36:54 INFO blockmanagement.BlockManager: maxReplication = 512
13/12/29 02:36:54 INFO blockmanagement.BlockManager: minReplication = 1
13/12/29 02:36:54 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
13/12/29 02:36:54 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false
13/12/29 02:36:54 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
13/12/29 02:36:54 INFO blockmanagement.BlockManager: encryptDataTransfer = false
13/12/29 02:36:54 INFO namenode.FSNamesystem: fsOwner = hdfs (auth:SIMPLE)
13/12/29 02:36:54 INFO namenode.FSNamesystem: supergroup = supergroup
13/12/29 02:36:54 INFO namenode.FSNamesystem: isPermissionEnabled = true
13/12/29 02:36:54 INFO namenode.FSNamesystem: HA Enabled: false
13/12/29 02:36:54 INFO namenode.FSNamesystem: Append Enabled: true
13/12/29 02:36:54 INFO util.GSet: Computing capacity for map INodeMap
13/12/29 02:36:54 INFO util.GSet: VM type = 64-bit
13/12/29 02:36:54 INFO util.GSet: 1.0% max memory = 96.7 MB
13/12/29 02:36:54 INFO util.GSet: capacity = 2^17 = 131072 entries
13/12/29 02:36:54 INFO namenode.NameNode: Caching file names occuring more than 10 times
13/12/29 02:36:54 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
13/12/29 02:36:54 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
13/12/29 02:36:54 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
13/12/29 02:36:54 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
13/12/29 02:36:54 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
13/12/29 02:36:54 INFO util.GSet: Computing capacity for map Namenode Retry Cache
13/12/29 02:36:54 INFO util.GSet: VM type = 64-bit
13/12/29 02:36:54 INFO util.GSet: 0.029999999329447746% max memory = 96.7 MB
13/12/29 02:36:54 INFO util.GSet: capacity = 2^12 = 4096 entries
13/12/29 02:36:55 INFO common.Storage: Storage directory $CONFIG/data/hadoop/hdfs/nn has been successfully formatted.
13/12/29 02:36:56 INFO namenode.FSImage: Saving image file $CONFIG/data/hadoop/hdfs/nn/current/fsimage.ckpt_0000000000000000000 using no compression
13/12/29 02:36:56 INFO namenode.FSImage: Image file $CONFIG/data/hadoop/hdfs/nn/current/fsimage.ckpt_0000000000000000000 of size 196 bytes saved in 0 seconds.
13/12/29 02:36:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
13/12/29 02:36:56 INFO util.ExitUtil: Exiting with status 0
13/12/29 02:36:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost.localdomain/127.0.0.x
************************************************************/
[hdfs@localhost bin]$
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Step 24: This command gives you information on hdfs system
[hdfs@localhost bin]$ ./hadoop dfsadmin -report
Configured Capacity: 16665448448 (15.52 GB)
Present Capacity: 12396371968 (11.55 GB)
DFS Remaining: 12396347392 (11.54 GB)
DFS Used: 24576 (24 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 1 (1 total, 0 dead)
Live datanodes:
Name: 127.0.0.x:50010 (localhost)
Hostname: localhost
Decommission Status : Normal
Configured Capacity: 16665448448 (15.52 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 4269076480 (3.98 GB)
DFS Remaining: 12396347392 (11.54 GB)
DFS Used%: 0.00%
DFS Remaining%: 74.38%
Last contact: Sun Dec 29 03:11:02 PST 2013
[hdfs@localhost bin]$
________________________________________________________
Step25: Stop all the services by running " stop-all.sh "
[hdfs@localhost sbin]$ ./stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [localhost]
localhost: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
localhost: stopping nodemanager
no proxyserver to stop
[hdfs@localhost sbin]$
________________________________________________________
Step 26: Start all the services by running "start-all.sh "
Added the YARN architecture block diagram to locate the presence of daemons in different components .

[hdfs@localhost sbin]$ ./start-all.sh
check the status of all services :
[hdfs@localhost sbin]$ jps
6161 NameNode
6260 DataNode
6719 NodeManager
6750 Jps
6355 SecondaryNameNode
6429 ResourceManager
[root@localhost bin]#
Job Definition and control Flow between Hadoop/Yarn components:
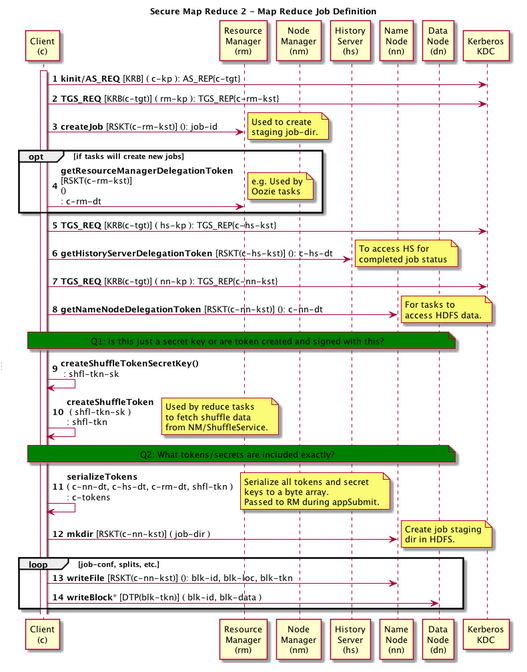 https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=31822268
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=31822268
________________________________________________________
Step 27: Run sample application program "pi" from hadoop-mapreduce-examples-2.2.0.jar
First test with hadoop to run existing hadoop program - launch the program, monitor progress, and get/put files on the HDFS. This program calculates the value of " pi " in parallel i.e 2 maps with 10 samples:
$ hadoop jar $BIN/lib/hadoop/hadoop-examples.jar pi 2 10
[hdfs@localhost bin]$ ./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar pi 2 10
Number of Maps = 2
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Starting Job
13/12/29 04:33:12 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
13/12/29 04:33:13 INFO input.FileInputFormat: Total input paths to process : 2
13/12/29 04:33:13 INFO mapreduce.JobSubmitter: number of splits:2
13/12/29 04:33:14 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1388320369543_0001
13/12/29 04:33:15 INFO impl.YarnClientImpl: Submitted application application_1388320369543_0001 to ResourceManager at /0.0.0.0:8032
13/12/29 04:33:15 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1388320369543_0001/
13/12/29 04:33:15 INFO mapreduce.Job: Running job: job_1388320369543_0001
13/12/29 04:33:38 INFO mapreduce.Job: Job job_1388320369543_0001 running in uber mode : false
13/12/29 04:33:38 INFO mapreduce.Job: map 0% reduce 0%
13/12/29 04:35:22 INFO mapreduce.Job: map 83% reduce 0%
13/12/29 04:35:23 INFO mapreduce.Job: map 100% reduce 0%
13/12/29 04:36:10 INFO mapreduce.Job: map 100% reduce 100%
13/12/29 04:36:16 INFO mapreduce.Job: Job job_1388320369543_0001 completed successfully
13/12/29 04:36:16 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=238681
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=528
HDFS: Number of bytes written=215
HDFS: Number of read operations=11
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=208977
Total time spent by all reduces in occupied slots (ms)=39840
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=292
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=1712
CPU time spent (ms)=3320
Physical memory (bytes) snapshot=454049792
Virtual memory (bytes) snapshot=3515953152
Total committed heap usage (bytes)=268247040
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 184.356 seconds
Estimated value of Pi is 3.80000000000000000000
[hdfs@localhost bin]$
________________________________________________________________
Step 28 : Verify the Running Services Using the Web Interface:
Web Interface for the resource Manager can be viewed by
http://localhost:8088
__________________________________________________________________
Step 29 : Create a Directory on HDFS
[hdfs@localhost bin]$ ./hadoop fs -mkdir test1
-------------------------------------------------------------------------
Step 30: Put local file "hellofile" into HDFS (/test1)
[hdfs@localhost bin]$ ./hadoop fs -put hellofile /test1
-------------------------------------------------------------------------
Step 31: Check the input file "hellofile" on HDFS
[hdfs@localhost bin]$ ./hadoop fs -ls /test1
Found 1 items
-rw-r--r-- 1 hdfs supergroup 113 2013-12-29 04:56 /test1/hellofile
[hdfs@localhost bin]$
___________________________________________________________
Step 32: Run application program "WordCount" from hadoop-mapreduce-examples-2.2.0.jar
WordCount Example:
WordCount example reads text files and counts how often words occur. The input is text files and the output is text files, each line of which contains a word and the count of how often it occured, separated by a tab.Each mapper takes a line as input and breaks it into words. It then emits a key/value pair of the word and 1. Each reducer sums the counts for each word and emits a single key/value with the word and sum.
To run the example, the command syntax is
bin/hadoop jar hadoop-*-examples.jar wordcount <in-dir> <out-dir>
All of the files in the input directory (called in-dir in the command line above) are read and the counts of words in the input are written to the output directory (called out-dir above).It is assumed that both inputs and outputs are stored in HDFS.If your input is not already in HDFS, but is rather in a local file system somewhere, you need to copy the data into HDFS as shown in above steps 29-31.
NOTE: Similarly you could think of processing bigger Data Files ( Weather data , Healthcare data, Machine Log data ...etc).
[hdfs@localhost bin]$ ./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /test1/hellofile /test1/output
13/12/29 04:57:51 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
13/12/29 04:57:53 INFO input.FileInputFormat: Total input paths to process : 1
13/12/29 04:57:53 INFO mapreduce.JobSubmitter: number of splits:1
13/12/29 04:57:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1388320369543_0002
13/12/29 04:57:55 INFO impl.YarnClientImpl: Submitted application application_1388320369543_0002 to ResourceManager at /0.0.0.0:8032
13/12/29 04:57:55 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1388320369543_0002/
13/12/29 04:57:55 INFO mapreduce.Job: Running job: job_1388320369543_0002
13/12/29 04:58:06 INFO mapreduce.Job: Job job_1388320369543_0002 running in uber mode : false
13/12/29 04:58:06 INFO mapreduce.Job: map 0% reduce 0%
13/12/29 04:58:17 INFO mapreduce.Job: map 100% reduce 0%
13/12/29 04:58:41 INFO mapreduce.Job: map 100% reduce 100%
13/12/29 04:58:42 INFO mapreduce.Job: Job job_1388320369543_0002 completed successfully
13/12/29 04:58:42 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=152
FILE: Number of bytes written=158589
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=215
HDFS: Number of bytes written=94
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=9934
Total time spent by all reduces in occupied slots (ms)=19948
Map-Reduce Framework
Map input records=4
Map output records=21
Map output bytes=194
Map output materialized bytes=152
Input split bytes=102
Combine input records=21
Combine output records=13
Reduce input groups=13
Reduce shuffle bytes=152
Reduce input records=13
Reduce output records=13
Spilled Records=26
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=148
CPU time spent (ms)=1520
Physical memory (bytes) snapshot=298029056
Virtual memory (bytes) snapshot=2346151936
Total committed heap usage (bytes)=143855616
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=113
File Output Format Counters
Bytes Written=94
[hdfs@localhost bin]$
Verify the Running Services Using the Web Interface:
_______________________________________________________
Step 33: View the output file of WorrdCount application program :
[hdfs@localhost bin]$ ./hadoop fs -ls /test1/output1
Found 2 items
-rw-r--r-- 1 hdfs supergroup 0 2013-12-29 05:09 /test1/output1/_SUCCESS
-rw-r--r-- 1 hdfs supergroup 120 2013-12-29 05:09 /test1/output1/part-r-00000

[hdfs@localhost bin]$ ./hadoop fs -ls /test1/output1/part-r-00000
Found 1 items
-rw-r--r-- 1 hdfs supergroup 120 2013-12-29 05:09 /test1/output1/part-r-00000
[hdfs@localhost bin]$ ./hadoop fs -cat /test1/output1/part-r-00000
Hello 693
Others 231
all 231
and 462
are 231
dear 231
everyone 462
friends 231
here 462
my 231
there 462
to 693
who 231
[hdfs@localhost bin]$

________________________________________________________________
References:
1) http://hadoop.apache.org/
2) Hadoop: The Definitive Guide by Tom White http://it-ebooks.info/book/635/

3) http://hortonworks.com/hadoop/
4) http://www.cloudera.com/content/cloudera/en/home.html
5) http://www.meetup.com/lspe-in/pages/7th_Event_-_Hadoop_Hands_on_Session/
----------------------------------------------------------------------------------------------------------
This is small effort to make familiar with Hadoop YARN setup to run some MapReduce applications and to execute POSIX commands in HDFS environment and also to verify the output for Data analytics.There are many other configurations that you can set for history server/checkpoint/type of Scheduler.. etc which are very much required in production environment (That will be documented separately)
------------------
Click here : Overview of Hadoop .
Click here : Multi-node Cluster setup and Implementation.
Click here: Big Data Revolution and Vision ........!!!
Click here : Big Data : Watson - Era of cognitive computing !!!
End of YARN Single node Installation . :)
************************************************************/
13/12/29 02:36:52 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library //hadoop-2.2.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
13/12/29 02:36:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Formatting using clusterid: CID-d47a364a-edc6-455f-b3c8-4d2ba54458d5
13/12/29 02:36:54 INFO namenode.HostFileManager: read includes:
HostSet(
)
13/12/29 02:36:54 INFO namenode.HostFileManager: read excludes:
HostSet(
)
13/12/29 02:36:54 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
13/12/29 02:36:54 INFO util.GSet: Computing capacity for map BlocksMap
13/12/29 02:36:54 INFO util.GSet: VM type = 64-bit
13/12/29 02:36:54 INFO util.GSet: 2.0% max memory = 96.7 MB
13/12/29 02:36:54 INFO util.GSet: capacity = 2^18 = 262144 entries
13/12/29 02:36:54 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
13/12/29 02:36:54 INFO blockmanagement.BlockManager: defaultReplication = 1
13/12/29 02:36:54 INFO blockmanagement.BlockManager: maxReplication = 512
13/12/29 02:36:54 INFO blockmanagement.BlockManager: minReplication = 1
13/12/29 02:36:54 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
13/12/29 02:36:54 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false
13/12/29 02:36:54 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
13/12/29 02:36:54 INFO blockmanagement.BlockManager: encryptDataTransfer = false
13/12/29 02:36:54 INFO namenode.FSNamesystem: fsOwner = hdfs (auth:SIMPLE)
13/12/29 02:36:54 INFO namenode.FSNamesystem: supergroup = supergroup
13/12/29 02:36:54 INFO namenode.FSNamesystem: isPermissionEnabled = true
13/12/29 02:36:54 INFO namenode.FSNamesystem: HA Enabled: false
13/12/29 02:36:54 INFO namenode.FSNamesystem: Append Enabled: true
13/12/29 02:36:54 INFO util.GSet: Computing capacity for map INodeMap
13/12/29 02:36:54 INFO util.GSet: VM type = 64-bit
13/12/29 02:36:54 INFO util.GSet: 1.0% max memory = 96.7 MB
13/12/29 02:36:54 INFO util.GSet: capacity = 2^17 = 131072 entries
13/12/29 02:36:54 INFO namenode.NameNode: Caching file names occuring more than 10 times
13/12/29 02:36:54 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
13/12/29 02:36:54 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
13/12/29 02:36:54 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
13/12/29 02:36:54 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
13/12/29 02:36:54 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
13/12/29 02:36:54 INFO util.GSet: Computing capacity for map Namenode Retry Cache
13/12/29 02:36:54 INFO util.GSet: VM type = 64-bit
13/12/29 02:36:54 INFO util.GSet: 0.029999999329447746% max memory = 96.7 MB
13/12/29 02:36:54 INFO util.GSet: capacity = 2^12 = 4096 entries
13/12/29 02:36:55 INFO common.Storage: Storage directory $CONFIG/data/hadoop/hdfs/nn has been successfully formatted.
13/12/29 02:36:56 INFO namenode.FSImage: Saving image file $CONFIG/data/hadoop/hdfs/nn/current/fsimage.ckpt_0000000000000000000 using no compression
13/12/29 02:36:56 INFO namenode.FSImage: Image file $CONFIG/data/hadoop/hdfs/nn/current/fsimage.ckpt_0000000000000000000 of size 196 bytes saved in 0 seconds.
13/12/29 02:36:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
13/12/29 02:36:56 INFO util.ExitUtil: Exiting with status 0
13/12/29 02:36:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost.localdomain/127.0.0.x
************************************************************/
[hdfs@localhost bin]$
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Step 14: Start HDFS service - Namenode Daemon process
$cd ../sbin
[hdfs@localhost bin]$ cd ../sbin/
[hdfs@localhost sbin]$ ./hadoop-daemon.sh start namenode
starting namenode, logging to /$PACKAGE_HOME/hadoop-2.2.0/logs/hadoop-hdfs-namenode localhost.localdomain.out
Step 15: Check the status of namenode daemon
[hdfs@localhost ]$ jps
4537 Jps
4300 NameNode =====> started successfully
[hdfs@localhost sbin]$ ps -ef | grep java
hdfs 4300 1 11 02:38 pts/1 00:00:04 $BIN/java/default/bin/java -Dproc_namenode -Xmx100m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=$PACKAGE_HOME/hadoop-2.2.0 -Dhadoop.id.str=hdfs -Dhadoop.root.logger=INFO,console -Djava.library.path=$PACKAGE_HOME/hadoop-2.2.0/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dhadoop.log.file=hadoop-hdfs-namenode-localhost.localdomain.log -Dhadoop.home.dir=$PACKAGE_HOME/hadoop-2.2.0 -Dhadoop.id.str=hdfs -Dhadoop.root.logger=INFO,RFA -Djava.library.path=$PACKAGE_HOME/hadoop-2.2.0/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.namenode.NameNode
_______________________________________________________________________________
Step 16 : Start HDFS service - Secondary Namenode Daemon process
[hdfs@localhost sbin]$ ./hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to $PACKAGE_HOME/hadoop-2.2.0/logs/hadoop-hdfs-secondarynamenode-localhost.localdomain.out
[hdfs@localhost sbin]$
Step 17 : Check the status of Secondarynamenode daemon
[hdfs@localhost bin]$ jps
4300 NameNode
4913 SecondaryNameNode ======> started successfully
[hdfs@localhost sbin]$ ps -ef | grep java | grep 4913
hdfs 4913 1 7 02:46 pts/1 00:00:04 $BIN/java/default/bin/java -Dproc_secondarynamenode -Xmx100m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=$PACKAGE_HOME/hadoop-2.2.0 -Dhadoop.id.str=hdfs -Dhadoop.root.logger=INFO,console -Djava.library.path=$PACKAGE_HOME/hadoop-2.2.0/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dhadoop.log.file=hadoop-hdfs-secondarynamenode-localhost.localdomain.log -Dhadoop.home.dir=$PACKAGE_HOME/hadoop-2.2.0 -Dhadoop.id.str=hdfs -Dhadoop.root.logger=INFO,RFA -Djava.library.path=$PACKAGE_HOME/hadoop-2.2.0/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
_____________________________________________________________________________________________________________
Step 18: Start HDFS service - DataNode Daemon process
[hdfs@localhost sbin]$ ./hadoop-daemon.sh start datanode
starting datanode, logging to $PACKAGE_HOME/hadoop-2.2.0/logs/hadoop-hdfs-datanode-localhost.localdomain.out
[hdfs@localhost sbin]$
Step 19: Check the status of Datanode daemon
[hdfs@localhost bin]$ jps
4300 NameNode
4913 SecondaryNameNode
4949 Jps
4373 DataNode ======> started successfully
[hdfs@localhost sbin]$ ps -ef | grep java | grep 4373
hdfs 4373 1 34 02:39 pts/1 00:00:06 $BIN/java/default/bin/java -Dproc_datanode -Xmx100m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=$PACKAGE_HOME/hadoop-2.2.0 -Dhadoop.id.str=hdfs -Dhadoop.root.logger=INFO,console -Djava.library.path=$PACKAGE_HOME/hadoop-2.2.0/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dhadoop.log.file=hadoop-hdfs-datanode-localhost.localdomain.log -Dhadoop.home.dir=$PACKAGE_HOME/hadoop-2.2.0 -Dhadoop.id.str=hdfs -Dhadoop.root.logger=INFO,RFA -Djava.library.path=$PACKAGE_HOME/hadoop-2.2.0/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -server -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.datanode.DataNode
___________________________________________________________________
Step 20:Start YARN service - resourcemanager Daemon process
[hdfs@localhost sbin]$ ./yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to $PACKAGE_HOME/hadoop-2.2.0/logs/yarn-hdfs-resourcemanager-localhost.localdomain.out
Step 21 : Check the status of ResourceManager daemon
[hdfs@localhost bin]$ jps
4300 NameNode
4913 SecondaryNameNode
4949 Jps
4373 DataNode
4500 ResourceManager ======> started successfully
[hdfs@localhost sbin]$ ps -ef | grep java | grep 4500
hdfs 4500 1 3 02:41 pts/1 00:00:08 $BIN/java/default/bin/java -Dproc_resourcemanager -Xmx200m -Dhadoop.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dyarn.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dhadoop.log.file=yarn-hdfs-resourcemanager-localhost.localdomain.log -Dyarn.log.file=yarn-hdfs-resourcemanager-localhost.localdomain.log -Dyarn.home.dir= -Dyarn.id.str=hdfs -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=$PACKAGE_HOME/hadoop-2.2.0/lib/native -Dyarn.policy.file=hadoop-policy.xml -Dhadoop.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dyarn.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dhadoop.log.file=yarn-hdfs-resourcemanager-localhost.localdomain.log -Dyarn.log.file=yarn-hdfs-resourcemanager-localhost.localdomain.log -Dyarn.home.dir=$PACKAGE_HOME/hadoop-2.2.0 -Dhadoop.home.dir=$PACKAGE_HOME/hadoop-2.2.0 -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=$PACKAGE_HOME/hadoop-2.2.0/lib/native -classpath $PACKAGE_HOME/hadoop-2.2.0/etc/hadoop/:$PACKAGE_HOME/hadoop-2.2.0/etc/hadoop/:$PACKAGE_HOME/hadoop-2.2.0/etc/hadoop/:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/common/lib/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/common/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/hdfs:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/hdfs/lib/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/hdfs/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/yarn/lib/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/yarn/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/mapreduce/lib/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/mapreduce/*:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/yarn/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/yarn/lib/*:$PACKAGE_HOME/hadoop-2.2.0/etc/hadoop//rm-config/log4j.properties org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
_____________________
Step 22:Start YARN service - NodeManager Daemon process
[hdfs@localhost sbin]$ ./yarn-daemon.sh start nodemanager
starting nodemanager, logging to $PACKAGE_HOME/hadoop-2.2.0/logs/yarn-hdfs-nodemanager-localhost.localdomain.out
[hdfs@localhost sbin]$
Step 23 : Check the status of Nodemanager daemon
[hdfs@localhost bin]$ jps
4300 NameNode
4744 NodeManager ======> started successfully
4913 SecondaryNameNode
4949 Jps
4373 DataNode
4500 ResourceManager
[root@localhost bin]#
[hdfs@localhost sbin]$ ps -ef | grep java | grep 4744
hdfs 4744 1 2 02:42 pts/1 00:00:03 $BIN/java/default/bin/java -Dproc_nodemanager -Xmx200m -Dhadoop.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dyarn.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dhadoop.log.file=yarn-hdfs-nodemanager-localhost.localdomain.log -Dyarn.log.file=yarn-hdfs-nodemanager-localhost.localdomain.log -Dyarn.home.dir= -Dyarn.id.str=hdfs -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=$PACKAGE_HOME/hadoop-2.2.0/lib/native -Dyarn.policy.file=hadoop-policy.xml -server -Dhadoop.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dyarn.log.dir=$PACKAGE_HOME/hadoop-2.2.0/logs -Dhadoop.log.file=yarn-hdfs-nodemanager-localhost.localdomain.log -Dyarn.log.file=yarn-hdfs-nodemanager-localhost.localdomain.log -Dyarn.home.dir=$PACKAGE_HOME/hadoop-2.2.0 -Dhadoop.home.dir=$PACKAGE_HOME/hadoop-2.2.0 -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=$PACKAGE_HOME/hadoop-2.2.0/lib/native -classpath $PACKAGE_HOME/hadoop-2.2.0/etc/hadoop/:$PACKAGE_HOME/hadoop-2.2.0/etc/hadoop/:$PACKAGE_HOME/hadoop-2.2.0/etc/hadoop/:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/common/lib/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/common/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/hdfs:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/hdfs/lib/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/hdfs/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/yarn/lib/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/yarn/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/mapreduce/lib/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/mapreduce/*:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/yarn/*:$PACKAGE_HOME/hadoop-2.2.0/share/hadoop/yarn/lib/*:$PACKAGE_HOME/hadoop-2.2.0/etc/hadoop//nm-config/log4j.properties org.apache.hadoop.yarn.server.nodemanager.NodeManager ________________________________________________________Step 24: This command gives you information on hdfs system
[hdfs@localhost bin]$ ./hadoop dfsadmin -report
Configured Capacity: 16665448448 (15.52 GB)
Present Capacity: 12396371968 (11.55 GB)
DFS Remaining: 12396347392 (11.54 GB)
DFS Used: 24576 (24 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 1 (1 total, 0 dead)
Live datanodes:
Name: 127.0.0.x:50010 (localhost)
Hostname: localhost
Decommission Status : Normal
Configured Capacity: 16665448448 (15.52 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 4269076480 (3.98 GB)
DFS Remaining: 12396347392 (11.54 GB)
DFS Used%: 0.00%
DFS Remaining%: 74.38%
Last contact: Sun Dec 29 03:11:02 PST 2013
[hdfs@localhost bin]$
________________________________________________________
Step25: Stop all the services by running " stop-all.sh "
[hdfs@localhost sbin]$ ./stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [localhost]
localhost: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
localhost: stopping nodemanager
no proxyserver to stop
[hdfs@localhost sbin]$
________________________________________________________
Step 26: Start all the services by running "start-all.sh "
Added the YARN architecture block diagram to locate the presence of daemons in different components .

[hdfs@localhost sbin]$ ./start-all.sh
check the status of all services :
[hdfs@localhost sbin]$ jps
6161 NameNode
6260 DataNode
6719 NodeManager
6750 Jps
6355 SecondaryNameNode
6429 ResourceManager
[root@localhost bin]#
Job Definition and control Flow between Hadoop/Yarn components:

________________________________________________________
Step 27: Run sample application program "pi" from hadoop-mapreduce-examples-2.2.0.jar
First test with hadoop to run existing hadoop program - launch the program, monitor progress, and get/put files on the HDFS. This program calculates the value of " pi " in parallel i.e 2 maps with 10 samples:
$ hadoop jar $BIN/lib/hadoop/hadoop-examples.jar pi 2 10
[hdfs@localhost bin]$ ./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar pi 2 10
Number of Maps = 2
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Starting Job
13/12/29 04:33:12 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
13/12/29 04:33:13 INFO input.FileInputFormat: Total input paths to process : 2
13/12/29 04:33:13 INFO mapreduce.JobSubmitter: number of splits:2
13/12/29 04:33:14 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1388320369543_0001
13/12/29 04:33:15 INFO impl.YarnClientImpl: Submitted application application_1388320369543_0001 to ResourceManager at /0.0.0.0:8032
13/12/29 04:33:15 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1388320369543_0001/
13/12/29 04:33:15 INFO mapreduce.Job: Running job: job_1388320369543_0001
13/12/29 04:33:38 INFO mapreduce.Job: Job job_1388320369543_0001 running in uber mode : false
13/12/29 04:33:38 INFO mapreduce.Job: map 0% reduce 0%
13/12/29 04:35:22 INFO mapreduce.Job: map 83% reduce 0%
13/12/29 04:35:23 INFO mapreduce.Job: map 100% reduce 0%
13/12/29 04:36:10 INFO mapreduce.Job: map 100% reduce 100%
13/12/29 04:36:16 INFO mapreduce.Job: Job job_1388320369543_0001 completed successfully
13/12/29 04:36:16 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=238681
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=528
HDFS: Number of bytes written=215
HDFS: Number of read operations=11
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=208977
Total time spent by all reduces in occupied slots (ms)=39840
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=292
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=1712
CPU time spent (ms)=3320
Physical memory (bytes) snapshot=454049792
Virtual memory (bytes) snapshot=3515953152
Total committed heap usage (bytes)=268247040
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 184.356 seconds
Estimated value of Pi is 3.80000000000000000000
[hdfs@localhost bin]$
________________________________________________________________
Step 28 : Verify the Running Services Using the Web Interface:
Web Interface for the resource Manager can be viewed by
http://localhost:8088
 |
| Shows the running application on single node cluster |
 |
| Application Overview -Final Status( FINISHED) |
Step 29 : Create a Directory on HDFS
[hdfs@localhost bin]$ ./hadoop fs -mkdir test1
-------------------------------------------------------------------------
Step 30: Put local file "hellofile" into HDFS (/test1)
[hdfs@localhost bin]$ ./hadoop fs -put hellofile /test1
-------------------------------------------------------------------------
Step 31: Check the input file "hellofile" on HDFS
[hdfs@localhost bin]$ ./hadoop fs -ls /test1
Found 1 items
-rw-r--r-- 1 hdfs supergroup 113 2013-12-29 04:56 /test1/hellofile
[hdfs@localhost bin]$
___________________________________________________________
Step 32: Run application program "WordCount" from hadoop-mapreduce-examples-2.2.0.jar
WordCount Example:
WordCount example reads text files and counts how often words occur. The input is text files and the output is text files, each line of which contains a word and the count of how often it occured, separated by a tab.Each mapper takes a line as input and breaks it into words. It then emits a key/value pair of the word and 1. Each reducer sums the counts for each word and emits a single key/value with the word and sum.
To run the example, the command syntax is
bin/hadoop jar hadoop-*-examples.jar wordcount <in-dir> <out-dir>
All of the files in the input directory (called in-dir in the command line above) are read and the counts of words in the input are written to the output directory (called out-dir above).It is assumed that both inputs and outputs are stored in HDFS.If your input is not already in HDFS, but is rather in a local file system somewhere, you need to copy the data into HDFS as shown in above steps 29-31.
NOTE: Similarly you could think of processing bigger Data Files ( Weather data , Healthcare data, Machine Log data ...etc).
[hdfs@localhost bin]$ ./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /test1/hellofile /test1/output
13/12/29 04:57:51 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
13/12/29 04:57:53 INFO input.FileInputFormat: Total input paths to process : 1
13/12/29 04:57:53 INFO mapreduce.JobSubmitter: number of splits:1
13/12/29 04:57:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1388320369543_0002
13/12/29 04:57:55 INFO impl.YarnClientImpl: Submitted application application_1388320369543_0002 to ResourceManager at /0.0.0.0:8032
13/12/29 04:57:55 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1388320369543_0002/
13/12/29 04:57:55 INFO mapreduce.Job: Running job: job_1388320369543_0002
13/12/29 04:58:06 INFO mapreduce.Job: Job job_1388320369543_0002 running in uber mode : false
13/12/29 04:58:06 INFO mapreduce.Job: map 0% reduce 0%
13/12/29 04:58:17 INFO mapreduce.Job: map 100% reduce 0%
13/12/29 04:58:41 INFO mapreduce.Job: map 100% reduce 100%
13/12/29 04:58:42 INFO mapreduce.Job: Job job_1388320369543_0002 completed successfully
13/12/29 04:58:42 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=152
FILE: Number of bytes written=158589
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=215
HDFS: Number of bytes written=94
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=9934
Total time spent by all reduces in occupied slots (ms)=19948
Map-Reduce Framework
Map input records=4
Map output records=21
Map output bytes=194
Map output materialized bytes=152
Input split bytes=102
Combine input records=21
Combine output records=13
Reduce input groups=13
Reduce shuffle bytes=152
Reduce input records=13
Reduce output records=13
Spilled Records=26
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=148
CPU time spent (ms)=1520
Physical memory (bytes) snapshot=298029056
Virtual memory (bytes) snapshot=2346151936
Total committed heap usage (bytes)=143855616
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=113
File Output Format Counters
Bytes Written=94
[hdfs@localhost bin]$
Verify the Running Services Using the Web Interface:
 |
| All Applications |
 |
| Scheduler-View on Web Interface |
Step 33: View the output file of WorrdCount application program :
[hdfs@localhost bin]$ ./hadoop fs -ls /test1/output1
Found 2 items
-rw-r--r-- 1 hdfs supergroup 0 2013-12-29 05:09 /test1/output1/_SUCCESS
-rw-r--r-- 1 hdfs supergroup 120 2013-12-29 05:09 /test1/output1/part-r-00000

[hdfs@localhost bin]$ ./hadoop fs -ls /test1/output1/part-r-00000
Found 1 items
-rw-r--r-- 1 hdfs supergroup 120 2013-12-29 05:09 /test1/output1/part-r-00000
[hdfs@localhost bin]$ ./hadoop fs -cat /test1/output1/part-r-00000
Hello 693
Others 231
all 231
and 462
are 231
dear 231
everyone 462
friends 231
here 462
my 231
there 462
to 693
who 231
[hdfs@localhost bin]$

________________________________________________________________
References:
1) http://hadoop.apache.org/
2) Hadoop: The Definitive Guide by Tom White http://it-ebooks.info/book/635/

3) http://hortonworks.com/hadoop/
4) http://www.cloudera.com/content/cloudera/en/home.html
5) http://www.meetup.com/lspe-in/pages/7th_Event_-_Hadoop_Hands_on_Session/
----------------------------------------------------------------------------------------------------------
This is small effort to make familiar with Hadoop YARN setup to run some MapReduce applications and to execute POSIX commands in HDFS environment and also to verify the output for Data analytics.There are many other configurations that you can set for history server/checkpoint/type of Scheduler.. etc which are very much required in production environment (That will be documented separately)
------------------
Click here : Overview of Hadoop .
Click here : Multi-node Cluster setup and Implementation.
Click here: Big Data Revolution and Vision ........!!!
Click here : Big Data : Watson - Era of cognitive computing !!!
End of YARN Single node Installation . :)
No comments:
Post a Comment