High-performance computing means the use of multiple CPU/GPU cores and parallel
processing, but there are many ways to address the software
implementation. Accelerator-based heterogeneous computing is gaining momentum in the high-performance computing arena. However, the increased complexity of heterogeneous architectures demands more generic, high-level programming models. OpenACC is one such attempt to tackle this problem. Many modern parallel computing systems are heterogeneous at their node level. Such nodes may comprise general purpose CPUs and accelerators (such as, GPU, or Intel Xeon Phi or FPGA) that provide high performance with suitable energy-consumption characteristics. There are various parallel programming approaches (such as OpenMP, OpenACC, OpenCL, CUDA) and selecting the one that is suitable for a target context is pretty challenging. OpenMP and OpenACC are directive based programming approaches. whereas, OpenCL and Cuda are parallel computing frameworks that enable
programming languages such as C, C++,python and Fortran. Besides the obvious use-case of a Graphics Processing Unit (GPU), namely rendering 3D object, it is also possible to perform general-purpose computations using frameworks like OpenCL or CUDA. (well known use-case is bitcoin mining).Other interesting use-case: image processing.
 |
| HPC Parallel Computing Platforms and Methodologies |
GPGPU is the utilization of a GPU (graphics processing unit), which would typically only handle computer graphics, to assist in performing tasks that are traditionally handled solely by the CPU (central processing unit). GPGPU allows information to be transferred in both directions, from CPU to GPU and GPU to CPU. Such bidirectional processing can hugely improve efficiency in a wide variety of tasks related to images and video. If the application you use supports OpenCL or CUDA, you will normally see huge performance boosts when using hardware that supports the relevant GPGPU framework.
NVIDIA was an early and aggressive advocate of leveraging graphics
processors for other massively parallel processing tasks (often referred
to as general-purpose computing on graphics processing units, or
GPGPU). However, GPGPU has been embraced in the HPC (high-performance computing)
server space, and NVIDIA is the dominant supplier of GPUs for HPC. CUDA (Compute Unified Device Architecture) is a parallel computing platform and programming model for NVIDIA GPUs (Graphics Processing Units) and
NVidia's proprietary parallel computing programming model. CUDA provides an interface to NVIDIA GPUs through a variety of programming languages, libraries, and APIs.
A
"CUDA Core" is NVidia's equivalent to AMD's "Stream Processors". AMD
acknowledges that it is there with the company's
ROCm (Radeon Open Compute Platform) initiative.
AMD is behind, but that doesn’t mean they’re not trying to catch up. When CUDA was first introduced by Nvidia, the name was an acronym for Compute Unified Device Architecture, but Nvidia subsequently dropped the common use of the acronym.
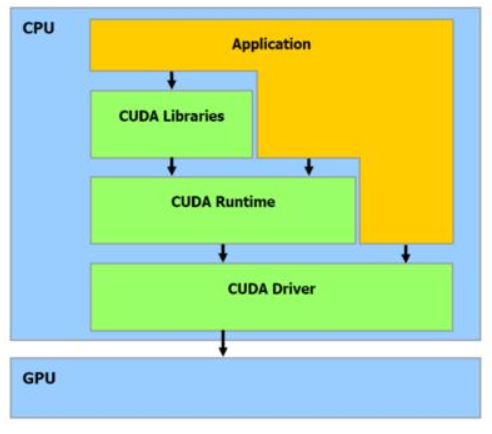
CUDA provides both a low level API (CUDA Driver API, non single-source) and a higher level API (CUDA Runtime API, single-source). The CUDA runtime makes it possible to compile and link your CUDA kernels into executable. This means that you don't have to distribute cubin files with your application, or deal with loading them through the driver API. As you have noted, it is generally easier to use. In contrast, the driver API is harder to program but provided more control over how CUDA is used. The programmer has to directly deal with initialization, module loading, etc. Apparently more detailed device information can be queried through the driver API than through the runtime API. For instance, the free memory available on the device can be queried only through the driver API.
NOTE:Parallel portions of an application are executed on the device as kernels. Many CUDA threads execute each kernel at a time. Cuda threads are large in number (say 1000) compared with muti-core CPU threads. A cuda kernel is executed by array of threads and all threads run the same code. Here , Device=GPU, HOST=CPU,Kernel=function that runs on device.
OpenCL™ (Open Computing Language) framework is the open, royalty-free standard for cross-platform, parallel programming of diverse processors found in personal computers, servers, mobile devices and embedded platforms. OpenCL greatly improves the speed and responsiveness of a wide spectrum of applications in numerous market categories including gaming and entertainment titles, scientific and medical software, professional creative tools, vision processing, and neural network training and inferencing. It is maintained by the industrial consortium Khronos. OpenCL 2.2 brings the OpenCL C++ kernel language into the core specification for significantly enhanced parallel programming productivity. Developers program at a higher level than OpenCL C or C++, but always
have access to lower-level code through seamless integration with
OpenCL, C/C++ libraries, and frameworks such as OpenCV™ [Open Computer Vision] or OpenMP™ [Open Multi Processing].
OpenCV (Open source computer vision) is a library of programming functions mainly aimed at real-time computer vision developed by Intel. In simple language it is library used for Image Processing. It is mainly used to do all the operation related to Images. OpenCV supports a lot of algorithms related to Computer Vision and Machine Learning OpenCV is written in C++ and its primary interface is in C++. OpenCV-Python is the Python API of OpenCV. It combines the best qualities of OpenCV C++ API and Python language. It will use optimized routines to accelerate. Interfaces (1) & (2) are also under active development for high-speed GPU operations.
1) A CUDA-based GPU interface
2) An OpenCL-based GPU interface
OpenMP and OpenACC enable directive-based parallel programming.OpenMPI tries to take advantage of multiple CPU cores, OpenAcc tries to utilize the GPU cores. OpenMP enables parallel programming on shared-memory computing platforms, as for example multi-core CPUs. It is very easy to use, since it is sufficient to tell the compiler some directives (code annotations, or pragmas) on how to extract the parallelism which triggers the synthesis of a parallel version of the input source code. OpenACC is a collection of compiler directives to specify parts of a C/C++ or Fortran code to be accelerated by an attached accelerator, as a GPU. It follows pretty much the same philosophy of OpenMP and enables creating high-level host+accelerator programs, again without the need of managing the accelerator programming language. For example, OpenACC will let you simply accelerate existing C/C++ codes without needing to learn CUDA (with some performance penalty, of course). OpenACC enables hybrid CPU+GPU programming. You can also mix OpenMP and OpenACC directives. For example, in a 4-GPU system, you can create 4 CPU threads to offload computing work to the 4 available GPUs. This is described in the Shane Cook book. However, it should be mentioned that OpenMP 4.0 foresees also directives for offloading work to attached accelerators.Often considered siblings, OpenMP and OpenACC share a long list of similarities, but with a few notable differences driven by philosophy. While OpenMP believes compilers are dumb and users are smart, the OpenACC mantra in compilers can be smart, and even smarter with the user’s help. For example, OpenMP isn’t dependency-aware and will attempt to parallel whatever the user requests, while OpenACC will refuse to parallel if the compiler detects an error.
The main difference between OpenGL and OpenCL is that the OpenGL is used for graphics programming while the OpenCL is used for heterogeneous computing. OpenGL is a cross-platform application programming interface (API) for rendering 2D and 3D vector graphics [create 2D (Triangle, Polygons, and Hexagons, etc.) and 3D objects (Cube, Sphere, and Torus, etc.)] while OpenCL is a framework for writing programs that execute across heterogeneous platforms where developers write programs for systems with multiple CPUs, GPUs, Digital Signal Processors (DSP), Field Programmable Gate Arrays (FPGAs), etc. Both OpenGL and OpenCL are managed by Khronos Group.
How do OpenCL and CUDA fit into the equation? OpenCL is currently the
leading open source GPGPU framework. CUDA, on the other hand, is the
leading proprietary GPGPU framework. It should be noted that Nvidia
cards actually support OpenCL as well as CUDA, they just aren’t quite as
efficient as AMD GPUs when it comes to OpenCL computation .Unlike OpenCL, CUDA-enabled GPUs are only available from Nvidia.
CUDA and OpenCL offer two different interfaces for programming GPUs. OpenCL is an open standard that can be used to program CPUs, GPUs, and other devices from different vendors, while CUDA is specific to NVIDIA GPUs. Although OpenCL promises a portable language for GPU programming, its generality may entail a performance penalty. CUDA can be used in two different ways, (1) via the runtime API, which provides a C-like set of routines and extensions, and (2), via the driver API, which provides lower level control over the hardware but requires more code and programming effort. Both OpenCL and CUDA call a piece of code that runs on the GPU a kernel. OpenCL promises a portable language for GPU programming, capable of targeting very dissimilar parallel processing devices. Unlike a CUDA kernel, an OpenCL kernel can be compiled at runtime, which would add to an OpenCL’s running time. On the other hand, this just-in-time compile may allow the compiler to generate code that makes better use of the target GPU.
To compete with CUDA, AMD has shifted from OpenCL to its ROCm platform. AMD is also developing a thin "HIP" compatibility layer that compiles to either CUDA or ROCm. AMD's hipBLAS, hipSPARSE, and hipDNN all translate to the cu- or roc- equivalents, depending on hardware target. So, for example, hipBLAS would link to either cuBLAS or rocBLAS. On the hardware side, AMD's Radeon VII now looks competitive with, e.g. Nvidia's 2080 Ti. AMD now offers HIP, which converts CUDA, such that it
works on both AMD and NVIDIA hardware. Once the
CUDA-code has been translated successfully, software can run on both
NVIDIA and AMD hardware without problems.
NOTE: OpenCL and OpenACC are generic frameworks for heterogeneous programming
using CPU and accelerator devices such as GPUs. They have contrasting
features: the former explicitly controls devices through API functions,
while the latter generates such procedures along a guide of the
directives inserted by a programmer.
OpenACC and OpenCL may be candidates
- Dealing with inside the node
- Part of a standardization initiative
- OpenACC complementary to OpenCL
OpenACC and OpenMP focuses parallelism within a single "shared" node. OpenACC is a directives-based programming approach to parallel computing designed for performance and portability on CPUs and GPUs for HPC. Adding OpenACC has given the ability to migrate medium-sized simulations from a multi-node CPU cluster to a single multi-GPU server.Compiler uses these directives to automatically generate device specific application code [NO programming with vendor specific languages]. We already know that OpenMP has been making programming CPUs easy and portable. Similarly, a directive-based programming model for accelerators is OpenACC that is gaining popularity since the directives play an important role in developing portable software for GPUs. A combination of OpenMP and OpenACC, a hybrid model, is a plausible solution to port scientific applications to heterogeneous architectures especially when there is more than one GPU on a single node to port an application to.
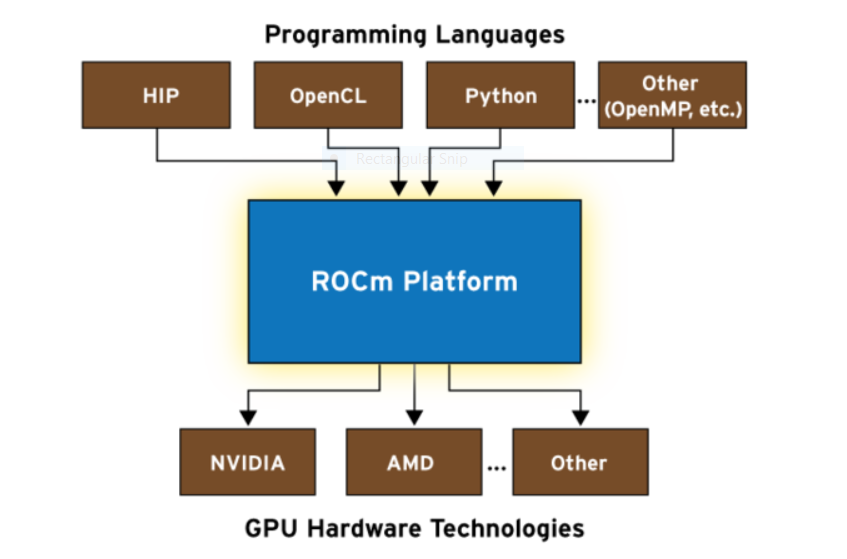
Radeon Open Compute Platform (ROCm) :
ROCm is a universal platform for GPU-accelerated computing. A modular design lets any hardware vendor build drivers that support the ROCm stack. ROCm also integrates multiple programming languages and makes it easy to add support for other languages.
The Department of Energy announced that Frontier, their forthcoming supercomputer in 2021, will have AMD Radeon Instinct GPUs. This is a $600M contract. It seems there will soon be growing pressure for cross-platform (Nvidia/AMD) programming models in the HPC space.The $600 million award marks the first system announcement to come out of the second CORAL (Collaboration of Oak Ridge, Argonne and Livermore) procurement process (CORAL-2). Poised to deliver “greater than 1.5 exaflops of HPC and AI processing performance,” Frontier (ORNL-5) will be based on Cray’s new Shasta architecture and Slingshot interconnect and will feature future-generation AMD Epyc CPUs and Radeon Instinct GPUs. This will start with Cray working with AMD to enhance these tools for optimized GPU scaling with extensions for Radeon Open Compute Platform (ROCm). These software enhancements will leverage low-level integrations of AMD ROCmRDMA technology with Cray Slingshot to enable direct communication between the Slingshot NIC to read and write data directly to GPU memory for higher application performance.
Exploring AMD’s Ambitious ROCm Initiative :
AMD released the innovative ROCm hardware-accelerated, parallel computing environment, and since then, the company has continued to refine its bold vision for an open-source, multi-platform, high-performance computing environment. Over the past two years, ROCm developers have contributed many new features and components to the ROCm open software platform. Now, the much-anticipated release of the Vega 7nm technology based GPU environment adds another important ingredient to the mix, empowering a second generation of high-performance applications that will benefit from ROCm’s acceleration features and “write it once” programming paradigm.
ROCm is a universal platform for GPU-accelerated computing. A modular
design lets any hardware vendor build drivers that support the ROCm
stack. ROCm also integrates multiple programming languages and makes it
easy to add support for other languages. ROCm even provides tools for
porting vendor-specific CUDA code into a vendor-neutral ROCm format,
which makes the massive body of source code written for CUDA available
to AMD hardware and other hardware environments.
ROCm is designed as a universal platform, supporting multiple languages and GPU technologies.
Lower in the stack, ROCm provides the Heterogeneous Computing Platform, a
Linux driver, and a runtime stack optimized for “HPC and ultra-scale
class computing.” ROCm’s modular design means the programming stack is
easily ported to other environments.
At the heart of the ROCm platform is the Heterogeneous Compute Compiler
(HCC). The open source HCC is based on the LLVM compiler with the Clang
C++ preprocessor. HCC supports several versions of standard C++,
including C++11, C++14, and some C++17 features. HCC also supports
GPU-based acceleration and other parallel programming features,
providing a path for programmers to access the advanced capabilities of
AMD GPUs in the same way that the proprietary NVCC CUDA compiler
provides access to NVIDIA hardware.
Important features include the following:
- Multi-GPU coarse-grain shared virtual memory
- Process concurrency and preemption
- Large memory allocations
- HSA signals and atomics
- User-mode queues and DMA
- Standardized loader and code-object format
- Dynamics and offline-compilation support
- Peer-to-peer multi-GPU operation with RDMA support
- Profiler trace and event-collection API
- Systems-management API and tools
Solid Compilation Foundation and Language Support
- LLVM compiler foundation
- HCC C++ and HIP for application portability
- GCN assembler and disassembler
How does HIP work?
The below image explains it: CUDA gets converted to HIP and HIP gets compiled for the NVIDIA GPU with NVCC, and for the AMD GPU with their new C++ compiler HCC.
AMD announced its next-gen Navi-based Radeon RX 5700 and 5700 XT graphics cards recently.If you’re an AMD fan hoping that this will be the moment in history when
the company finally pulls ahead of Nvidia with a high-end video card —
like it may be doing against Intel with desktop CPUs — this isn’t that
moment. Despite its new Navi architecture, which offers 1.25x the
performance per clock and 1.5x performance per watt, these aren’t even
as high-end as AMD’s existing (and complicated) 13.8 TFLOP Radeon VII
GPU. At up to 9.75 TFLOPs and 7.95 TFLOPs of raw computing power
respectively, and with 8GB of GDDR6 memory instead of 16GB of HBM2, the
5700-series isn’t a world-beater.
Intel announced that its first "discrete" graphics chip (GPU) is coming in 2020. By "discrete GPU", the company means a graphics chip on its own, an entirely separate component that isn't integrated into a processor chip(CPU). Typically , Intel GPUs are integrated with its CPUs. Intel's GPU will be released in 2020 will be designed for enterprise applications like machine learning , as well as consumer level applications that benefit from the dedicated power of discrete GPUs.
We eagerly await doing the price/performance comparisons across these enterprise GPU compute engines.
Reference :
http://www.admin-magazine.com/HPC/Articles/Discovering-ROCm
https://www.bdti.com/InsideDSP/2016/12/15/AMD
https://www.khronos.org/opencl/
https://www.electronicdesign.com/embedded-revolution/choosing-parallelization-technique-what-s-best-path
https://sabripllana.eu/papers/arms_cc_2017.pdf
https://towardsdatascience.com/get-started-with-gpu-image-processing-15e34b787480













{kind=link}
{kind=link}
{kind=link}